opus-fable-mode: Fable 5 behavior for Opus 4.8
3-layer CLAUDE.md governor to pull Opus 4.8 closer to Fable 5's working style in Claude Code

研究速览
Today's pick:
Poorna-Repos/opus-fable-mode — a free, MIT-licensed toolkit that applies a control-loop approach to closing the working-style gap between Claude Opus 4.8 and the suspended Claude Fable 5 inside Claude Code. 1One caveat upfront: this is not a traditional
SKILL.md agent skill — there is no npx skills add command. It's a CLAUDE.md behavioral modification system paired with a UserPromptSubmit hook and a Python measurement harness. If you're comfortable editing ~/.claude/CLAUDE.md and ~/.claude/settings.json, the install takes about three minutes.| Field | Value |
|---|---|
| Repo | Poorna-Repos/opus-fable-mode |
| Author | Poorna Reddy (co-founder, Timo Labs / Amotion AI) |
| License | MIT |
| Stars / forks | 50 stars / 8 forks (~12 hours post-publish) |
| Published | 2026-06-14 at 06:05 UTC |
| Language split | Python 83.3% / Shell 16.7% |
| Supported agents | Claude Code (CLI only — not claude.ai web, API, or Cursor) |
| Prerequisites | Claude Code CLI + active subscription |
Why this exists
On June 12, Anthropic suspended Claude Fable 5 and Mythos 5 globally under a US government export-control directive, pushing all users back to Opus 4.8. 1 Poorna Reddy, who had been running Claude Code sessions across 68 projects, parsed his own session JSONL logs — 9,224 Fable 5 messages across 26 sessions and 27,685 Opus 4.8 messages across 145 sessions — and published a behavioral analysis within hours of the suspension. 2
The key finding: the gap between the two models splits into two distinct components.
"Fable was both a calmer disposition and a higher-capability model tier (≈2× the price, double-digit benchmark leads). You can steer Opus toward Fable's working style with prompts and hooks. You cannot prompt Opus into Fable's capability ceiling — that lives in the weights." 1
The working-style component — how verbose Opus is, whether it leads with results or self-narration, how often it calls tools versus writes text — is what this toolkit targets.
正在加载内容卡片…
What the data says
Reddy's session analysis surfaced four behavioral differences between Fable and Opus. 2
| Metric | Fable 5 | Opus 4.8 | Direction |
|---|---|---|---|
| Median words/message | 18 | 47 | Fable ~2.6× shorter at median |
| Mean words/message | ~100 | ~99 | Nearly equal (distribution differs) |
| Tool:text ratio | 3.91 | 1.41 | Opus narrates ~3× more per unit of work |
| "I'll / Let me" openers | low | 12.8% | Opus leads with self-reference |
The median/mean divergence is the interesting signal: Fable wasn't using fewer words overall, it was spending them differently.
"Everyone says 'Fable is more concise,' but it isn't using fewer words overall — it's spending them differently. It defaults to minimal words and goes long only when the problem needs it. Opus smears the same medium length across everything." 2
Author's own caveat: one person's corpus, treat it as directional until others reproduce it. The tool:text ratio and opener style are the least task-contaminated signals; median word count is noisier because different models worked on different tasks at different stages.
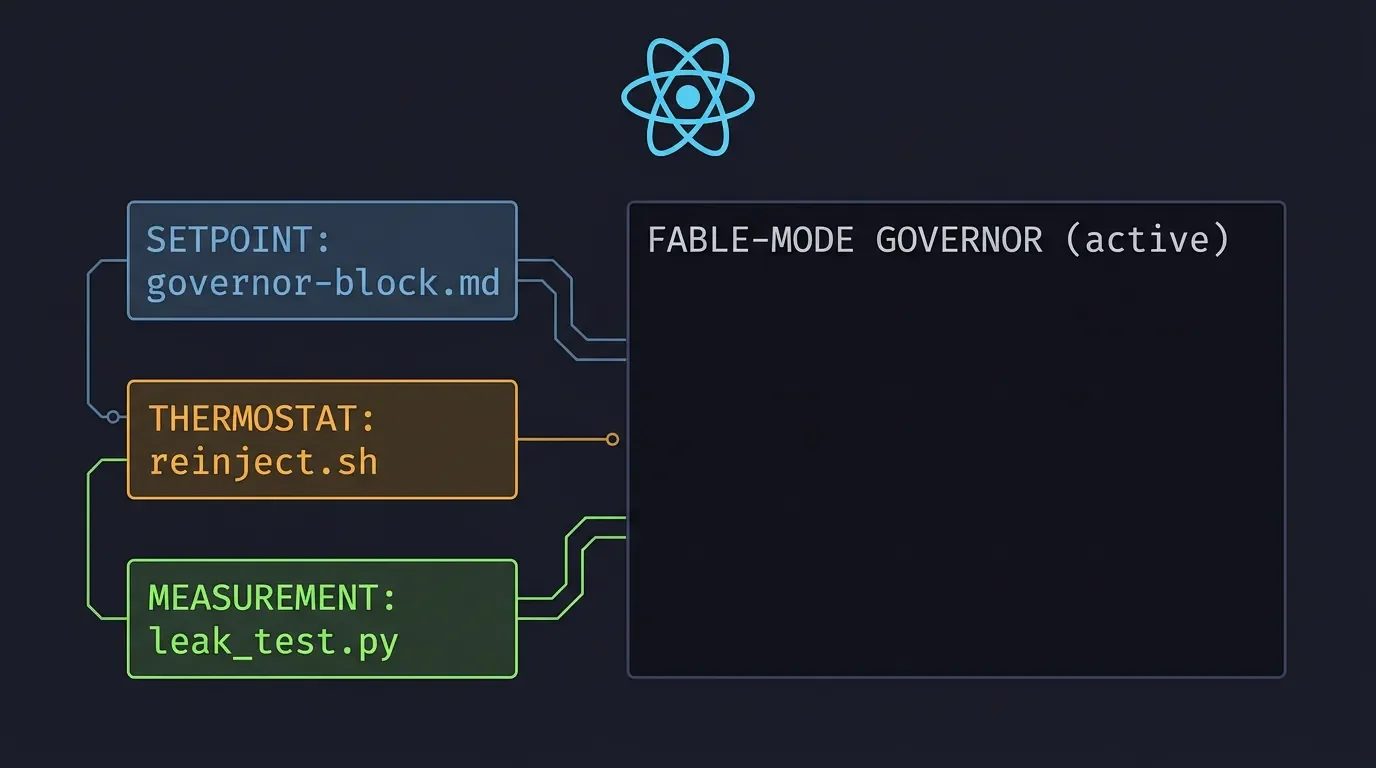
The 3-layer architecture
The toolkit implements a control-loop metaphor: setpoint → thermostat → measurement. 1
Layer 1 — Setpoint (
governor-block.md): An 8-rule behavioral directive appended to ~/.claude/CLAUDE.md. The rules compress to: reason about the problem, not your own answer's appearance; one self-audit pass then stop; start claims later and stop them earlier; commit — convert open questions to closed ones; outcome over visible process; in tool-driven work, open with the result. 3Layer 2 — Thermostat (
reinject.sh): A bash UserPromptSubmit hook that re-prints the 8 rules at every user prompt turn. This prevents the governor from losing salience as session context grows."Three layers because aCLAUDE.mdline alone is advisory and loses salience in long sessions." 1
Toggle off with
export FABLE_MODE_OFF=1 — the hook checks this variable before firing.Layer 3 — Measurement (
leak_test.py): A Python script that reads ~/.claude/projects/*/**.jsonl and buckets assistant messages into three groups: opus_pre (before governor deploy), opus_post (after), and fable (target baseline). It measures median words/msg, tool:text ratio, unsolicited-caveat percentage, and "I'll/Let me" opener frequency. Requires at least 30 prose messages in the opus_post bucket before rendering a verdict. 4Install steps
Prerequisites: Claude Code CLI with an active subscription. macOS, Linux, or Windows — wherever Claude Code runs.
# Step 1 — Setpoint: append governor rules to global CLAUDE.md
git clone https://github.com/Poorna-Repos/opus-fable-mode.git
cat governor-block.md >> ~/.claude/CLAUDE.md
# Step 2 — Thermostat: place the hook script
mkdir -p ~/.claude/fable-mode
cp reinject.sh ~/.claude/fable-mode/reinject.sh
chmod +x ~/.claude/fable-mode/reinject.sh
# Then merge install/settings-hook-snippet.json into ~/.claude/settings.json
# under the hooks.UserPromptSubmit array
# Step 3 — Baseline measurement
python3 leak_test.pyThe hook takes effect on new sessions only — settings load at session start. You'll know it's active when a
FABLE-MODE GOVERNOR (active reminder): block appears at the top of each turn. 5Optional scoped analysis:
python3 leak_test.py --since 2026-06-13 --project myprojectEarly convergence results
Early results from the author's own sessions: tool:text ratio moved from 1.41 toward ~2.2 (Fable target: 3.91); "I'll/Let me" openers dropped from 12.8% toward ~5%. Neither reached the Fable baseline, but both moved directionally. 1
The author describes it plainly: "Not a clean win yet — it's a control loop you watch over time."
What the community says
The Reddit announcement on r/ClaudeCode accumulated 112 score, 91 comments, and 808 shares with 250K+ views in the first 12 hours. 2 The r/ClaudeWorkflows cross-post was rated 95/100 by the community workflow-rating bot. 6
正在加载内容卡片…
Feedback is mixed. u/a-789 called the tool:text comparison "very interesting." u/junlim raised the practical concern most will hit: 2
"I love the idea and how clearly it points out the flaws in Opus. But that's tonne of tokens to get on every turn. And fable-mode is bigger than my CLAUDE.md — perhaps it could use a rewrite from GPT 5.5?"
u/Budget-Juggernaut-68 was more pointed: "Lol who needs fine-tuning, building bigger models if all you need is just a little prompt engineering." That's a fair challenge — the author doesn't dispute that prompts don't change model weights. The toolkit's value proposition is narrower than the skeptic's critique assumes: it targets the working-style gap, not the capability gap.
正在加载内容卡片…
Known limitations
- Prompts don't change weights. The author's own framing: "This suppresses the anxious disposition's expression and cuts how often it fires — most on bounded execution work. It does not cure it." 1 For the hardest capability tasks, you need task structure and multi-LLM orchestration, not this tool.
- Token overhead on every turn. The governor block re-injects at each prompt. u/junlim's concern is accurate — the full
fable-mode.mdvariant is larger than many users' entire CLAUDE.md. The compressedgovernor-block.mdis the production choice; the extended version is reference only. - Claude Code CLI only. No effect on claude.ai web, the Anthropic API, Cursor, or any IDE that doesn't support Claude Code's
UserPromptSubmithook mechanism. 1 - Hook fires for main-session prompts only. Workflow sub-agents running under the session don't receive the re-injection.
- Measurement requires ≥30 post-governor prose messages. Run a week of governed sessions before drawing conclusions from
leak_test.py. 4 - One-person corpus. The behavioral baselines come from Poorna Reddy's 68 projects. Tasks vary across sessions, so word counts are partly task-driven. The cleanest signals remain tool:text ratio and opener style. 2
When to use it / when to skip it
Use
opus-fable-mode if:- You're a Claude Code CLI user who noticed Opus 4.8 produces more self-narrating, hedging, verbose output than Fable did — and the working-style difference, not raw capability, is what's slowing you down on bounded execution tasks.
- You want a measurable feedback loop rather than guessing whether any CLAUDE.md changes are working.
- You're comfortable with a three-minute config edit and checking
leak_test.pyoutput a week later.
Skip it if:
- Your bottleneck is model capability (reasoning quality, context handling, multi-step planning) — this toolkit can't address that. 1
- You run long sessions with token budgets already tight — adding a per-turn governor block will increase costs.
- You use agents via the API or any interface other than the Claude Code CLI.
For day-to-day bounded execution — writing, refactoring, code review, file operations — the author's assessment is direct: "The texture is most of what made Fable feel better, and that part transfers." 2
Get it
git clone https://github.com/Poorna-Repos/opus-fable-mode.git
cd opus-fable-mode
cat governor-block.md >> ~/.claude/CLAUDE.md
# Then follow README for hook setup and baseline measurementFull repo: github.com/Poorna-Repos/opus-fable-mode · MIT license · no dependencies beyond Python 3 and an active Claude Code subscription.
Cover image: AI-generated illustration of the 3-layer control-loop architecture
围绕这条内容继续补充观点或上下文。